MXNet Gluon 上实现跨卡同步 Batch Normalization
· 张航 Amazon AI Applied Scientist很多用户在论坛上,GitHub 上,甚至是不同的深度学习平台上,都要求提供跨卡同步(Cross-GPU Synchronized) Batch Normalization 或称为同步BN (SyncBN)。 我们团队率先提供了 MXNet 的实现。
写在前面:为什么要跨卡同步 Batch Normalization
现有的标准 Batch Normalization 因为使用数据并行(Data Parallel),是单卡的实现模式,只对单个卡上对样本进行归一化,相当于减小了批量大小(batch-size)(详见BN工作原理部分)。 对于比较消耗显存的训练任务时,往往单卡上的相对批量过小,影响模型的收敛效果。 之前在我们在图像语义分割的实验中,Jerry和我就发现使用大模型的效果反而变差,实际上就是BN在作怪。 跨卡同步 Batch Normalization 可以使用全局的样本进行归一化,这样相当于‘增大‘了批量大小,这样训练效果不再受到使用 GPU 数量的影响。 最近在图像分割、物体检测的论文中,使用跨卡BN也会显著地提高实验效果,所以跨卡 BN 已然成为竞赛刷分、发论文的必备神器。
Batch Normalization如何工作
既然是技术贴,读者很多是深学大牛,为什么还要在这里赘述BatchNorm这个简单概念吗?其实不然,很多做科研的朋友如果没有解决过相关问题, 很容易混淆BN在训练和测试时候的工作方式。记得在17年CVPR的 tutoial 上, 何恺明和RBG两位大神分别在自己的talk上都特意强调了BN的工作原理,可见就算台下都是CV的学者,也有必要复习一遍这些知识。
- 工作原理:
BN 有效地加速了模型训练,加大 learning rate,让模型不再过度依赖初始化。它在训练时在网络内部进行归一化(normalization), 为训练提供了有效的 regularization,抑制过拟合,用原作者的话是防止了协方差偏移。这里上一张图来展示训练模式的BN:
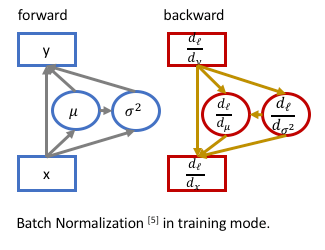
其中输入样本,其均值为,方差为, BN的输出,是可学习对参数。 个人认为,这种强大的效果其实来自于back-propagation时候,来自于均值和方差对输入样本的梯度( )。 这也是BN在训练模式与其在测试模式的重要区别,在测试模式(evaluation mode)下, 使用训练集上累积的均值和方差,在back-propagation的时候他们对输入样本没有梯度(gradient)。
- 数据并行:
深度学习平台在多卡(GPU)运算的时候都是采用的数据并行(DataParallel),如下图:
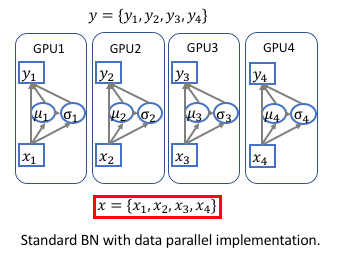
每次迭代,输入被等分成多份,然后分别在不同的卡上前向(forward)和后向(backward)运算,并且求出梯度,在迭代完成后合并 梯度、更新参数,再进行下一次迭代。因为在前向和后向运算的时候,每个卡上的模型是单独运算的,所以相应的Batch Normalization 也是在卡内完成,所以实际BN所归一化的样本数量仅仅局限于卡内,相当于批量大小(batch-size)减小了。
如何实现 SyncBN
跨卡同步BN的关键是在前向运算的时候拿到全局的均值和方差,在后向运算时候得到相应的全局梯度。
最简单的实现方法是先同步求均值,再发回各卡然后同步求方差,但是这样就同步了两次。实际上只需要同步一次就可以,
我们使用了一个非常简单的技巧,把方差表示为,
附上一张图:
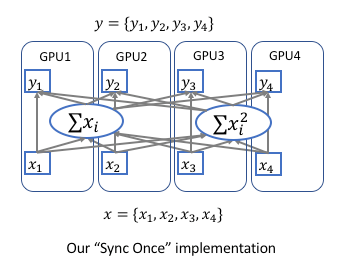
这样在前向运算的时候,我们只需要在各卡上算出与,再跨卡求出全局的和即可得到正确的均值和方差, 同理我们在后向运算的时候只需同步一次,求出相应的梯度与。 我们在最近的论文Context Encoding for Semantic Segmentation 里面也分享了这种同步一次的方法。
有了跨卡BN我们就不用担心模型过大用多卡影响收敛效果了,因为不管用多少张卡只要全局的批量大小一样,都会得到相同的效果。