AWS AI全面助力视频理解,GluonCV 0.6轻松复现前沿模型
· 朱毅 Amazon Applied Scientist视频理解是近几年非常流行的研究方向,因为视频是最接近于人眼的真实输入,分析时间序列上的图像变化有助于我们开发更强的计算机视觉。而在视频理解领域,最具代表性的研究方向就是动作识别。区别于以往的大部分图像任务,动作识别的主体是动作,而不是物体,比如唱,跳,rap,篮球。
所以动作识别功能可以为我们做些什么呢?现在大部分手机相册都会自动标注照片,把图片分为家庭,自拍,庆祝等等类别,方便查找。可是拍的短视频怎么办?试试视频动作识别,不论是家居遛狗,还是家里遛娃,还是出门滑雪,这些全都属于动作识别的范畴。AI模型给每个视频打上标签,然后生成一个年终精彩视频集锦,帮你留住今年的每一份美好。

动作识别还有很多实际的应用,比如视频监控和人体行为分析。而且,视频理解不仅仅是一个方向,它更是一种概念。所有的图像处理问题,加上时间这个维度后,就会变成新的问题,比如物体检测在时间轴上就变成了物体跟踪。正因为视频理解如此重要,近几年在学术和工业界都赚足了眼球。
然而有很多阻碍限制了视频从业者的步伐,比如庞大的数据集,缺乏易用可复现的代码库,找不到教程,没法部署到终端上等等。就以数据集为例,视频领域里一个比较流行的数据集Kinetics400的视频总帧数是ImageNet图片总数的100倍。有时候为了更好的理解时序信息,很多模型还需要提取光流。很早就有知乎小伙伴反映过,几百万的训练样本,光抽帧就抽的头疼,更别提抽光流了,头发都要被抽没了。

即使准备好了数据,训练一个SOTA的模型也要数天之久,更别提复现、调参或者进行新的研究探索了。所以在这次GluonCV release 0.6中,我们一一解决以上提到的痛点。经过最近几个月的复现和优化,GluonCV现在全面支持视频理解中的大量模型和常见数据集。我们还提供了易上手的教程,分布式的支持,快速的视频加载,好玩的应用实例和可复现的超参和结果,帮助大家分分钟上手视频理解,免去了重复造轮子的困扰。小伙伴们还不快快上车,赶上这波全民视频的热潮!
更多的模型和数据库支持
最近Facebook也刚刚开源了他们的视频理解库,PySlowFast。 相比而言,我们提供更多更全的模型和数据库的支持。下面的表格列出了我们在Kinetics400数据集上提供的预训练模型,
| Name | Segments | Input Length | Top-1 | Top-5 |
|---|---|---|---|---|
| inceptionv1_kinetics400 | 7 | 1 | 69.1 | 88.7 |
| inceptionv3_kinetics400 | 7 | 1 | 72.5 | 90.2 |
| resnet18_v1b_kinetics400 | 7 | 1 | 65.5 | 86.0 |
| resnet34_v1b_kinetics400 | 7 | 1 | 69.1 | 88.0 |
| resnet50_v1b_kinetics400 | 7 | 1 | 69.9 | 88.5 |
| resnet101_v1b_kinetics400 | 7 | 1 | 71.3 | 88.6 |
| resnet152_v1b_kinetics400 | 7 | 1 | 71.5 | 88.9 |
| i3d_inceptionv1_kinetics400 | 1 | 32 | 71.8 | 90.1 |
| i3d_inceptionv3_kinetics400 | 1 | 32 | 73.6 | 90.8 |
| i3d_resnet50_v1_kinetics400 | 1 | 32 | 74.0 | 91.0 |
| i3d_resnet101_v1_kinetics400 | 1 | 32 | 75.1 | 91.8 |
| i3d_nl5_resnet50_v1_kinetics400 | 1 | 32 | 75.2 | 91.6 |
| i3d_nl10_resnet50_v1_kinetics400 | 1 | 32 | 75.3 | 91.7 |
| i3d_nl5_resnet101_v1_kinetics400 | 1 | 32 | 76.0 | 92.1 |
| i3d_nl10_resnet101_v1_kinetics400 | 1 | 32 | 76.1 | 91.9 |
| slowfast_4x16_resnet50_kinetics400 | 1 | 36 | 75.3 | 91.8 |
| slowfast_8x8_resnet50_kinetics400 | 1 | 40 | 76.6 | 92.4 |
| slowfast_8x8_resnet101_kinetics400 | 1 | 40 | 77.2 | 92.8 |
模型的各种backbone,各种变体,应有尽有。只需一行net = get_model(model_name), 即可享用训练好的模型。同时,我们还支持UCF101, HMDB51和Something-Something-V2数据集,对ActivityNet,HACS,Moments in Time和AVA的支持正在赶来的路上。所有的训练脚本,超参数,训练日志和测试方式全都提供,轻松复现基线模型。
快速的视频加载
视频数据的预处理非常繁琐,而且费时费力。以Kinetics400数据集为例,存储它所有的视频数据需要450GB的硬盘空间。如果我们全部抽成视频帧来训练,就要占6.8T的硬盘空间。如果再抽取光流,大部分机器表示吃不消。即使我们有足够的硬盘空间来储存这些数据,大量的数据会造成训练时候的IO瓶颈,GPU利用率大部分时候是0,导致训练极其缓慢还浪费资源。
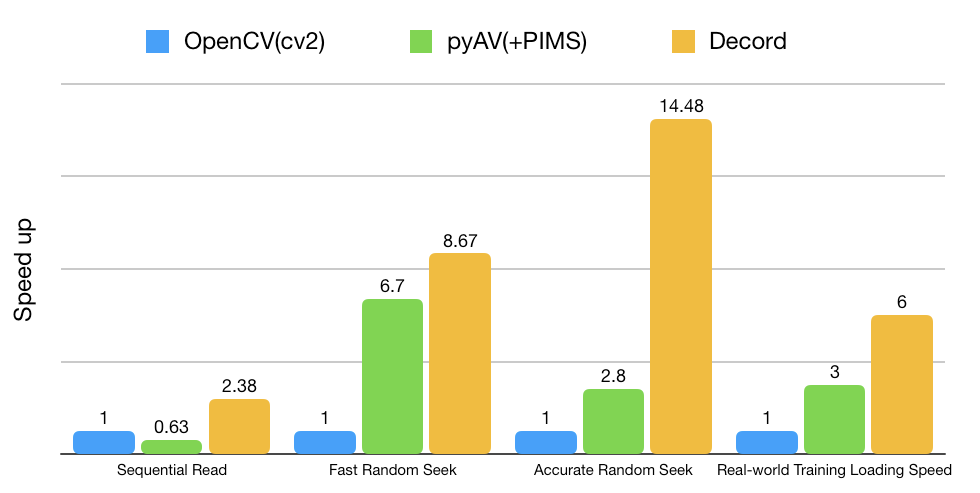
所以我们需要一个全新的视频加载器decord,可以直接读取视频,再也不用繁琐的预处理了, 想读哪帧读哪帧。
import decord
vr = decord.VideoReader('demo.mp4')
frames = vr.get_batch([1, 3, 5, 7])
print(frames.shape). # (4, 240, 320, 3)
如下图所示,相比已有的视频加载器,OpenCV和PyAV, 我们的decord至少快两倍以上,尤其在随机取帧的时候,更是快八倍以上,导师再也不用担心我的实验被卡IO了。
强大的自定义功能
我们提供了两个自定义的功能,自定义dataloader和自定义模型,帮助用户写最少的代码,实现最多的功能。
首先是自定义的dataloader,我们提供了一个VideoClsCustom的类,基本适用于大部分视频分类的任务。不论用户的数据是怎么存放,怎么命名, 什么格式的,只需要提供一个如下的文本文件就可以开始训练了。
root_path/xxx/video_001.mp4 200 0
root_path/xxx/video_001.avi 200 0
root_path/xxx/video_002.mp4 300 0
root_path/xxx/video_003.webm 100 1
......
root_path/xxx/video_100.mp4 200 10
每一行需要提供3个信息,分别是视频存放的路径,视频的长度以及视频的类别。如果用户已经将视频抽成了帧也不要紧, 只需要把对应视频路径换成视频帧文件夹的路径即可。比如我们现在要加载一个数据集,要随机从一段视频中抽取一个视频片段,长为64帧,隔帧取样,同时调整帧的大小为224x224。
train_dataset = VideoClsCustom(setting='train.txt',
new_length=32,
new_step=2,
new_height=224,
new_width=224)
还有很多默认的参数可以调整,满足大部分模型训练的需求,想了解更多选择请猛戳这里。
其次是自定义的模型,我们提供了几个常见模型的自定义版本,比如slowfast_4x16_resnet50_custom。用户在根据自己的数据集建立模型的时候,可以直接调用这个函数,只需要提供数据集里有几类就可以了。比如用一个视频异常检测的数据集做一个二分类问题,
net = get_model('slowfast_4x16_resnet50_custom', nclass=2)
在有了这两个自定义的功能后,用户基本无需写代码就可以直接在自己的数据集上自由的玩耍了。

丰富的教程
过去的五年,视频理解与行为识别快速发展,可是直到最近才陆陆续续有稳定的开源代码库,比如MMAction, PyVideoResearch, VMZ和PySlowFast。即便如此,简单易懂的教程依旧缺乏。我们GluonCV提供大量的jupyter notebook教程,用户可以直接本地体验,不论是在Windows,Linux还是Mac上。我们提供的教程包括如何复现SOTA模型,如何抽取特征,如何做推理,如何在自己的数据集上微调以及如何做分布式训练。
尤其值得一提的是分布式训练。鉴于视频领域训练太过耗时,训练一个SOTA模型动辄超过一周,最常见的方式就是使用分布式训练加速这个过程。可惜网上关于分布式训练的教程文档都非常少,更不要提专门针对视频模型讲解分布式训练的文档了。我们的教程包括如何设置集群通信,如何准备数据,如何启动分布式训练,一步步带你上手视频理解。我们的分布式训练扩展性能也很好,无需复杂的优化,两台机器即可提速1.6倍,四台机器可提速3.2倍, 八台机器可提速6倍。分布式训练可以帮助你快速迭代,是发论文做产品不可或缺的利器。
INT8量化,部署更快
GluonCV继续与英特尔携手带来更多的 INT8 量化模型。受益于Intel Deep Learning Boost(VNNI)的加持,用INT8 量化后的视频理解模型比它们原本的32位浮点数版本要快许多。因为是快速部署,我们只提供了部分2D模型的量化模型。下表是基于AWS EC2 C5实例的结果,在保持原有精度的情况下, 量化过的模型可以达到5倍的提速。
| Model | Dataset | Batch Size | Speedup (INT8/FP32) | FP32 Accuracy | INT8 Accuracy |
|---|---|---|---|---|---|
| vgg16_ucf101 | UCF101 | 64 | 4.46 | 81.86 | 81.41 |
| inceptionv3_ucf101 | UCF101 | 64 | 5.16 | 86.92 | 86.55 |
| inceptionv3_kinetics400 | Kinetics400 | 64 | 5.29 | 67.93 | 67.92 |
| resnet18_v1b_kinetics400 | Kinetics400 | 64 | 5.24 | 63.29 | 63.14 |
| resnet50_v1b_kinetics400 | Kinetics400 | 64 | 6.78 | 68.08 | 68.15 |
对于想要尝试的小伙伴, INT8量化版本的使用和标准的GluonCV模型一样,仅需在模型名称后加上_int8后缀,就可以体验性能起飞的感觉!同时, 为了方便用户在自有数据集上进行INT8量化,我们还提供了量化校准工具。目前本校准工具仅支持Hybridized后的Gluon模型,用户可以使用quantize_net接口来量化他们自己的模型, 方便各种部署。
相关链接
喜欢我们的工作并且希望支持更多的更新,欢迎点赞加星Fork!