GluonCV v0.4:更多更快
· 张帜 Amazon Applied ScientistGluonCV 0.3 版提供大量超越原论文精度的模型。0.4 版在此基础上引入了:
- 新应用:全新的人体关键点检测模型
- 更快的部署:新增 Int8 部署和经济适用型的删减版 ResNet(Pruned ResNet)系列
- 更强的预训练模型:ResNext, SE_ResNext 模型系列(各种 80%~81+% 准确度的 ImageNet 预训练模型)
- 支持 FPN 的 Faster/Mask-RCNN 系列
同时 GluonCV 现有模块的易用性和稳定性也得到了极大提升。
人体关键点检测
人体关键点检测用于描述人体的姿态进而分析人体行为,是非常基础的 CV 应用。GluonCV的人体关键点检测是一个完整独立的应用系列,不仅包含模型定义,训练脚本,损失和评估函数,同时还包括预训练模型参数和一系列使用教程。
部分小伙伴们春游的合照来镇场:

还有各种帅气的pose:

预训练的模型具体性能可以参考下表所示:
| Model | OKS AP | OKS AP with flip |
|---|---|---|
| simple_pose_resnet18_v1b | 66.3/89.2/73.4 | 68.4/90.3/75.7 |
| simple_pose_resnet18_v1b | 52.8/83.6/57.9 | 54.5/84.8/60.3 |
| simple_pose_resnet50_v1b | 71.0/91.2/78.6 | 72.2/92.2/79.9 |
| simple_pose_resnet50_v1d | 71.6/91.3/78.7 | 73.3/92.4/80.8 |
| simple_pose_resnet101_v1b | 72.4/92.2/79.8 | 73.7/92.3/81.1 |
| simple_pose_resnet101_v1d | 73.0/92.2/80.8 | 74.2/92.4/82.0 |
| simple_pose_resnet152_v1b | 72.4/92.1/79.6 | 74.2/92.3/82.1 |
| simple_pose_resnet152_v1d | 73.4/92.3/80.7 | 74.6/93.4/82.1 |
| simple_pose_resnet152_v1d | 74.8/92.3/82.0 | 76.1/92.4/83.2 |
可以看到我们提供的模型都可以达到极高的精度。
INT8加速部署
我们与 Intel 深度合作推出基于 Intel Deep Learning Boost(VNNI)的 Int8 quantization,在新一代 Intel CPU 的加持下,可以取得不俗的加速比。下图是基于 AWS EC2 C5 实例的初步结果:
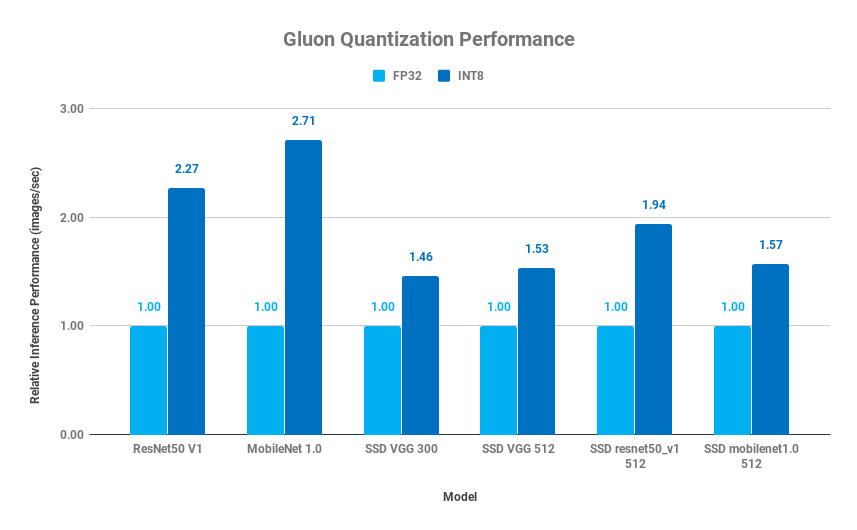
如何在保证准确度的情况下尽量使用较少的比特是一个相对复杂的过程,不过好在 0.4 版本目前已经内置了部分优化完的 INT8 网络,开盖即食(比如model_zoo中resnet50_v1_int8就是resnet50_v1INT8版本):
| Model | Dataset | Batch Size | C5.18x FP32 | C5.18x INT8 | Speedup | FP32 Acc | INT8 Acc |
|---|---|---|---|---|---|---|---|
| Resnet50_v1 | ImageNet | 128 | 122.02 | 276.72 | 2.27 | 77.21%/93.55% | 76.86%/93.46% |
| Mobilenet1.0 | ImageNet | 128 | 375.33 | 1016.39 | 2.71 | 73.28%/91.22% | 72.85%/90.99% |
| SSD 300 VGG16* | VOC | 224 | 21.55 | 31.47 | 1.46 | 77.4 | 77.46 |
| SSD 512 VGG16* | VOC | 224 | 7.63 | 11.69 | 1.53 | 78.41 | 78.39 |
| SSD 512 ResNet50* | VOC | 224 | 17.81 | 34.55 | 1.94 | 80.21 | 80.16 |
| SSD 512 Mobilenet1.0* | VOC | 224 | 31.13 | 48.72 | 1.57 | 75.42 | 75.04 |
*nms_thresh=0.45, nms_topk=200
之后的版本我们会引入 Gluon 接口的 INT8 转换函数,以方便部署各种模型(需要注意的是只有较新的 Intel CPU 能取得有效的加速,之后我们会有更详细的针对新硬件的博客)。
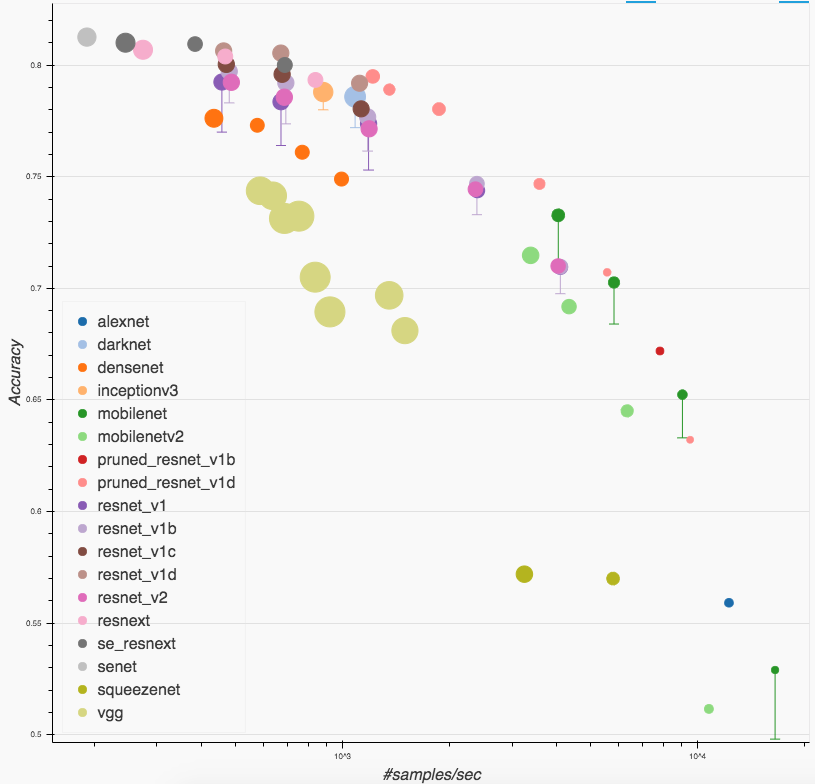
删减版ResNet
我们知道 CNN 的结构对于很多常见的任务都是高度冗余的,通过对预训练网络进行分析可以得到网络内部冗余度的权重。 之后我们可以删改网络的参数使得推导可以加速几倍到几十倍的同时不显著降低准确度。
道理说起来简单,也有大量的现成研究成果,不过 GluonCV 0.4 版把易用性做到了极致,下面表格里就是 0.4 版内置的删减版 ResNet 和他们的相对性能:
| Model | Top-1 | Top-5 | Hashtag | Speedup to original ResNet |
|---|---|---|---|---|
| resnet18_v1b_0.89 | 67.2 | 87.45 | 54f7742b | 2x |
| resnet50_v1d_0.86 | 78.02 | 93.82 | a230c33f | 1.68x |
| resnet50_v1d_0.48 | 74.66 | 92.34 | 0d3e69bb | 3.3x |
| resnet50_v1d_0.37 | 70.71 | 89.74 | 9982ae49 | 5.01x |
| resnet50_v1d_0.11 | 63.22 | 84.79 | 6a25eece | 8.78x |
| resnet101_v1d_0.76 | 79.46 | 94.69 | a872796b | 1.8x |
| resnet101_v1d_0.73 | 78.89 | 94.48 | 712fccb1 | 2.02x |
比如说resnet50_v1d_0.37表示一个权重是resnet50_v1d约 0.37 倍的模型,5.01x表示它的推导速度比原模型快约 5 倍。
更直观的对比可以参考下图或者交互版:
更多更有趣的GAN
超分辨率GAN(SRGAN)

以假乱真的CycleGAN

支持 FPN 的 Faster/Mask-RCNN
新增 FPN 支持的 Faster/Mask-RCNN,依然是SoTA的性能
| Model | GluonCV (bbox/seg mAP) | Reference (bbox/seg mAP) |
|---|---|---|
| faster_rcnn_fpn_resnet50_v1b_coco | 0.384/- | 0.379 |
| faster_rcnn_fpn_bn_resnet50_v1b_coco | 0.393/- | - |
| faster_rcnn_fpn_resnet101_v1d_coco | 0.412/- | 0.398/- |
| maskrcnn_fpn_resnet50_v1b_coco | 0.392/0.353 | 0.386/0.345 |
| maskrcnn_fpn_resnet101_v1d_coco | 0.423/0.377 | 0.409/0.364 |
易用性改进和Bug修复
Model Zoo里的 ResNet 都支持 Synchronized BatchNorm- 预训练完的目标检测模型都支持直接重置类别
reset_class,而且设置reuse_weights可以重用原本存在的类别。参考教程,我们可以无需任何训练就得到一个行人检测模型。 - 修复一些
DataLoader的问题(mxnet>=1.4.0) - 修复一些语义分隔模型无法
hybridize的问题 - 修复一些训练中随机
NaN的问题(需要mxnet nightly) - 修复一些 GPU 上 NMS 很慢的问题(需要mxnet nightly)
0.3 版训练技巧大公开
在 0.3 版中使用的训练技巧已经正式公开,想了解 GluonCV 超强预训练模型的小伙伴可以参考:
- Bag of Tricks for Image Classification with Convolutional Neural Networks
- Bag of Freebies for Training Object Detection Neural Networks
鸣谢
感谢所有在新版本中的贡献者:@xinyu-intel @hetong007 @zhreshold @khetan2 @chinakook @Jerryzcn @husonchen @zhanghang1989 @sufeidechabei @brettkoonce @mli @lgov @djl11 @YutingZhang @mzchtx @sharmalakshay93 @astonzhang @LcDog @zx-code123 @adursun @ifeherva @ZhennanQin @islinwh @jianantian @feynmanliang @ivechan @eric-haibin-lin
相关链接
喜欢我们的工作并且希望支持更多的更新,欢迎点赞加星Fork!
参考文献
[1] He T, Xie J, Zhang Z, et al. Bag of tricks for image classification with convolutional neural networks[J]. arXiv preprint arXiv:1812.01187, 2018.
[2] Zhang Z, He T, Zhang H, et al. Bag of Freebies for Training Object Detection Neural Networks[J]. arXiv preprint arXiv:1902.04103, 2019.
[3] Intel Deep Learning Boost. https://www.intel.ai/intel-deep-learning-boost
[4] Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 2223-2232.
[5] Ledig, Christian, et al. “Photo-realistic single image super-resolution using a generative adversarial network.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.