实战阿里天池竞赛——服饰属性标签识别
· 何通 Amazon AI Applied Scientist近期阿里巴巴的天池算法竞赛平台上线了有着高额奖金的 FashionAI全球挑战赛—服饰属性标签识别。第一名队伍将得到高达 50 万人民币的奖金!是不是非常动心?
反正我是动心了,可能有很多小伙伴也动心了。
为了帮助跃跃欲试的大家更好地上手这次比赛,我写了一个通过 gluon 训练模型的教程,从配置环境开始一步步带领大家训练出不错的模型。另外,我还提供一份能完整训练并参赛的脚本,让大家能够基本不做修改就马上进行训练并提交成绩。
比赛简介
首先,让我们来了解一下这个比赛的具体情况。主办方此次给出了真实线上商城的服饰图片,希望大家能够设计一个算法从图片上读出服饰的属性。什么是服饰的属性呢?这里的服饰属性可以简单地理解为不同的设计风格:对袖子来说,它的属性就可能是无袖,短袖还是长袖;对于衣领来说,它的属性就是娃娃领,衬衫领还是飞行员领等等。比赛的官方网站提供了如下的一张手绘图片,让大家更好地理解这个概念:
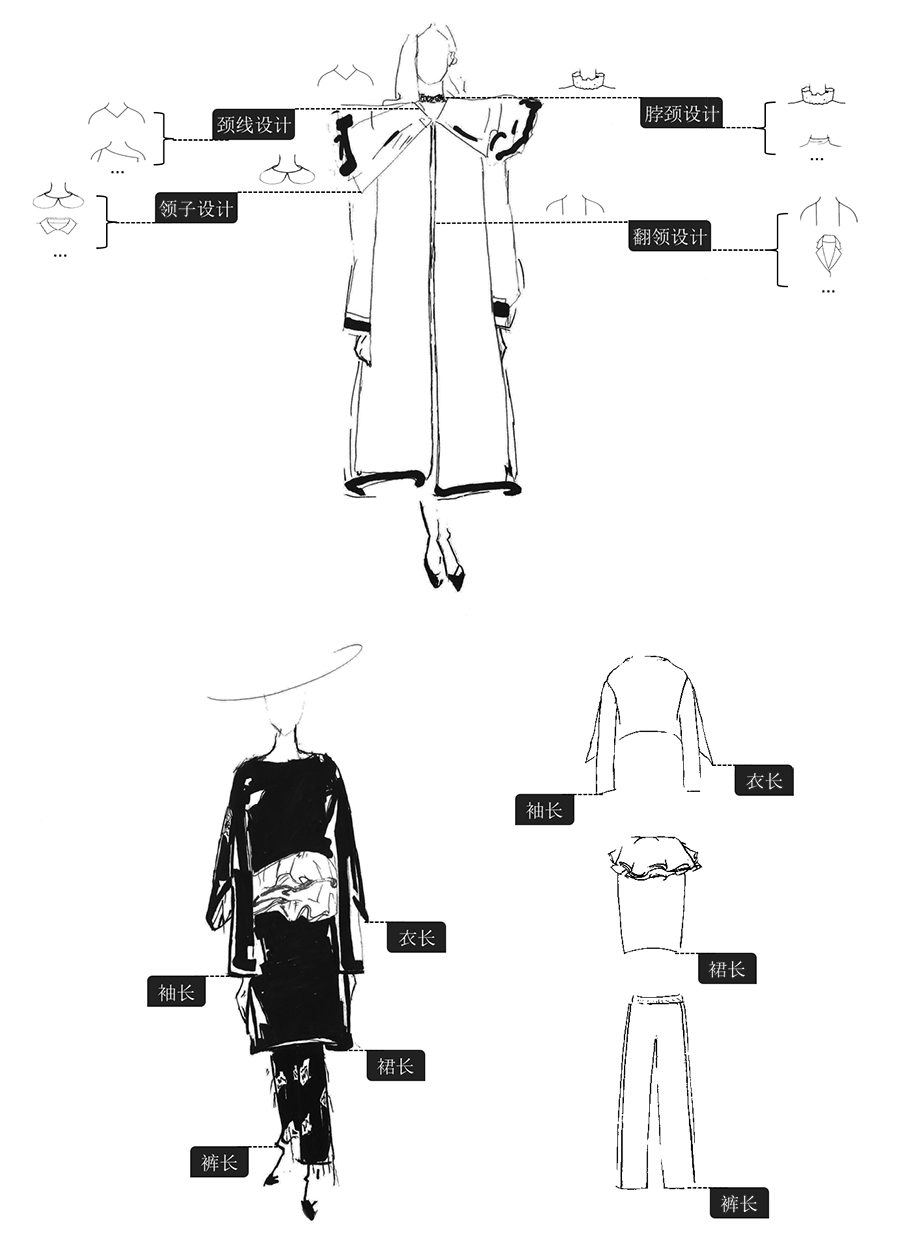
这次比赛分为初赛,复赛和决赛三个阶段。目前还处于初赛阶段,选手们能拿到的是八类服饰属性的图片数据,其中训练数据大约为 7 GB,测试数据大约为 800 MB。初赛会一直持续到 4 月 21 日,名列前 100 名的同学将获得晋级复赛的机会,届时主办方也将在复赛增加新的训练数据。
我们可以将这次比赛视为八个独立的图像分类问题,可以对每一种服饰分别训练一个模型。对于图片分类问题而言,当下最流行的模型当属卷积神经网络了。通过 gluon ,我们可以快速地开发并训练准确的卷积神经网络,进而在比赛中取得好的成绩。
为什么用 gluon ?
gluon 是我们最近为 mxnet 实现的 python 接口。你可能要问了,现在各路深度学习工具基本都有各自的 Python 接口,为什么还要用 gluon 呢?
各个工具的 Python 接口大致可以分为两类设计:符号式和命令式。如果用一句话来说明 gluon 的优势,那就是:gluon 能拿到命令式接口的便利之处,但仍然可以享受符号式的速度优势。
使用命令式接口时,你可以方便地以 “pythonic” 的代码搭建自己的模型与控制训练过程。有过实践经验的同学们应该了解,深度学习模型的训练是一个容错率很低的过程,命令式的接口能让用户方便地开发与调试 Python 代码。当然,这样的设计会带来一个众所周知的问题:用纯粹的 Python 代码来训练模型,可能会比较低效。
正因为命令式接口的效率问题,有不少接口选择了符号式的设计。符号式接口更高效,然而实现代码时通常需要经过下面的三个步骤:
- 定义计算流程
- 编译成可执行的程序
- 给定输入调用编译好的程序
当然,符号式接口的弱点也很明显,那就是难以实现与调试。
针对这两个问题, gluon 试着提出 一种解决方法,那就是以命令式接口的方法来写代码,然后还能以符号式接口的速度来训练模型。特别地,这个特性对于比赛参赛者而言也是很有吸引力的,因为参赛者需要方便地尝试各种模型、参数与技巧,同时也不能在模型训练上消耗过长时间浪费自己的提交机会。
参加比赛
你如果被上面一段说服了,那么就可以开始上手 gluon ,准备参加比赛了。约两周前,我公布了 这份代码库,希望能够为大家参赛提供一个不错的起点。
教程与样例代码
如果这是你的第一次深度学习竞赛甚至是第一次深度学习实践,那么请阅读参考 这一份教程。这份教程从环境配置出发,手把手地带你走过数据下载与整理,模型训练与分析等流程,最后也给出了一些提高成绩的改动方向。
如果你就想要一份代码跑跑看,先提交一次再说,那么可以参考 这个代码库 中的benchmark.sh 脚本来训练。这份脚本的结果提交后能达到大约 0.95 的榜上成绩,在这份代码刚实现时可以进入前 20。当然,在代码公布之后榜上分数水涨船高,为了进入前 100 参加复赛,大家需要付出越来越多的努力了。
迁移学习
在教程和样例代码中,我们选择了迁移学习的思想来训练模型。打个比方,迁移学习就是“站在巨人的肩膀上”,它的思路就是拿已经在别的数据上训练好的模型来再次训练。这样做的一个好处就是模型的起点比较高,相当于有了很多额外的训练数据,在比赛数据不是很丰富的情况下尤为有效。
我们为 gluon 用户提供了很多种不同的预训练模型,完整的列表和成绩可以参考 官方文档。在教程中,我们选择使用在 ImageNet 数据集上训练过的 ResNet50 V2 模型进行迁移学习。选择迁移学习模型时一般会考虑资源占用和准确率两个因素:
- 资源占用即再训练模型所需要的显存与耗时,一般会基于自己用来参赛的硬件条件来做相应选择。
- 准确率即模型在原数据集上达到的成绩,但要注意迁移学习并不保证原数据集上越准确的模型在新数据集上也一定越准确。
进阶提高
相信这份样例代码只是各位的起点,为了达到更好的成绩,选手们一般会尝试各种各样的改进。
下面我们给出关于如何改进的建议,你可以从它们出发,让自己的成绩更上一层楼:
- 调整参数,比如学习速率,批量大小,训练循环次数等。
- 参数之间是有互相影响的,比如更小的学习速率可能意味着更多的循环次数。
- 以验证集上的结果来选择参数。
- 不同任务上的最佳参数可能是不一样的,建议分别调整。
- 选择模型
- 在手头计算资源的限制下,尝试效果更好的模型。
- 更全面的图片增广
- 可以考虑在训练时加上更多的图片增广操作,例如色彩调整,增加噪音等。
- 集成学习
- 训练多个不同的好模型,然后将它们的预测结果平均起来。